
Common-Services develops the Flux module for Prestashop for Feed.biz and its joint offer with Cdiscount.
The problem is that Cdiscount has almost 15,000 possible product categories to date and has listed 44 million products since its creation.
The difficulty for the merchant is to be able to classify his products into these many categories correctly; and when a merchant has a large number of categories, it can become a real obstacle course.
The challenge for us initially was to achieve automatic categorisation, but due to the fact that Cdiscount does not communicate product descriptions via API calls that allow the catalogue to be consulted, we could only collect the names of products, which makes for a smaller volume of information, about 4 GB of data.
So, we took a different approach, deciding instead to model rather than to categorize; this allows the merchant to be offered generic models corresponding to its products: a list of probable categories, the type of product, the color attributes to be sent, whether or not different variants/versions are necessary etc.
To do do this, we implemented different available frameworks: TensortFlow, Keras, Nltk, CnnText, FastText.
The methodology is fairly simple in itself. It was enough to standardise, therefore rendering a complex text intelligible for the machine, on the one hand, the categories using the category code as a key, and on the other, the 44 million classified product names. The training procedure for all of these 44 million products took five hours on a machine with 32 CPUs running at 2.7 GHz and with 64 GB of RAM + 64 GB of RAM and a 400 GB hard disk as a temporary storage.
It was necessary to repeat this operation multiple times in order to correct all the small details that could cause problems, notably the punctuation.
Once the result was obtained, it was quite satisfactory: we obtained results able to reach a figure of up to 95% of accurate predictions.
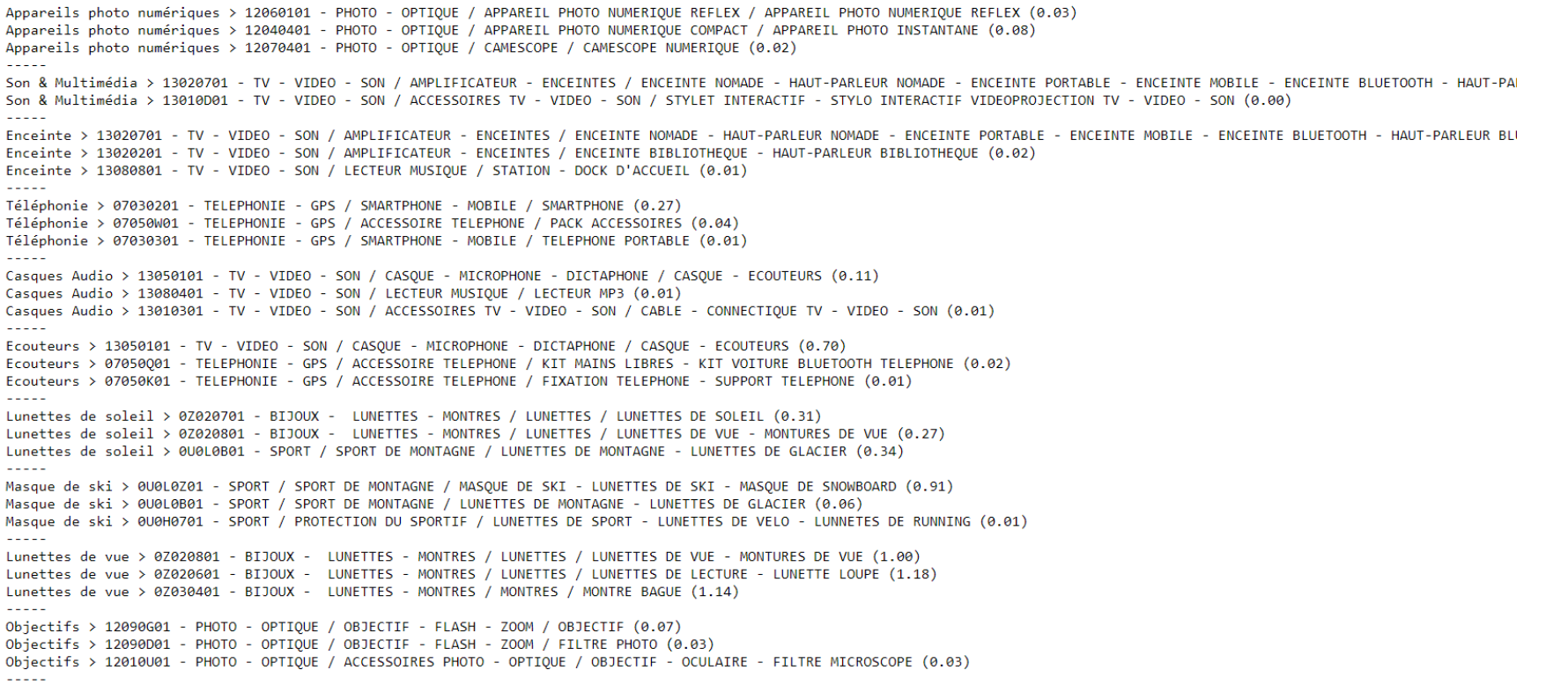
On the left, we have the category of the merchant who is not subjected to the learning machine. On the right, the category corresponding to Cdiscount. The data submitted is the entire content of the products of the categories of the merchant, without naming the category because this one could, for example, be called home! We can see that all the submitted products were given the most relevant Cdiscount categories as a suggestion.
Once this result was obtained, we were then able to create the corresponding probable models.
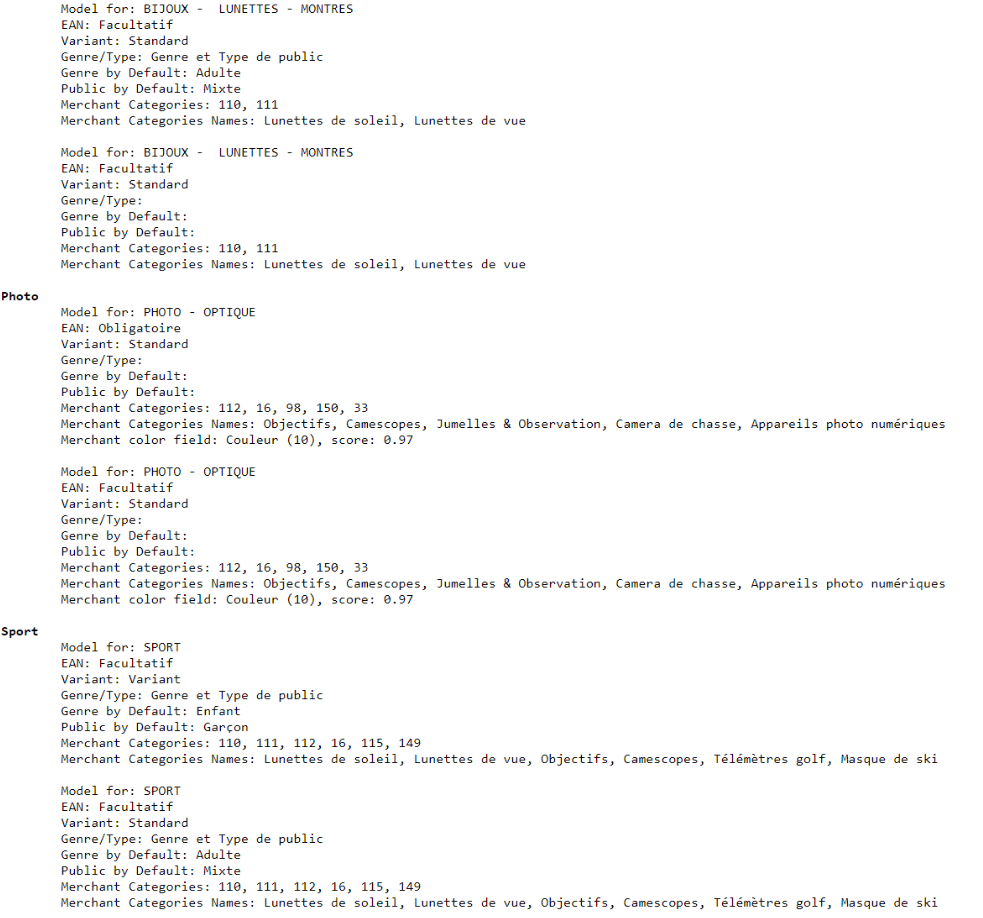
From the beginning of September, the merchant who submits a set of categories will be offered the most relevant models. He will only have to choose between a few rather than having to perform laborious mapping on 15000 categories!
We did the same thing for the size and color fields. For the color fields, we used a model based on negation: first, we inventoried all the colors and color variants, then we added the most obvious negations to the model, a maximum of oppositions: plane, dog, train, plate etc. The process is childishly simple and does not require cumbersome development.
Regarding the development needed for the modelling, this required more than 600 hours of work.
In staging environment, for a shoes sellers, for the “Sandals” category
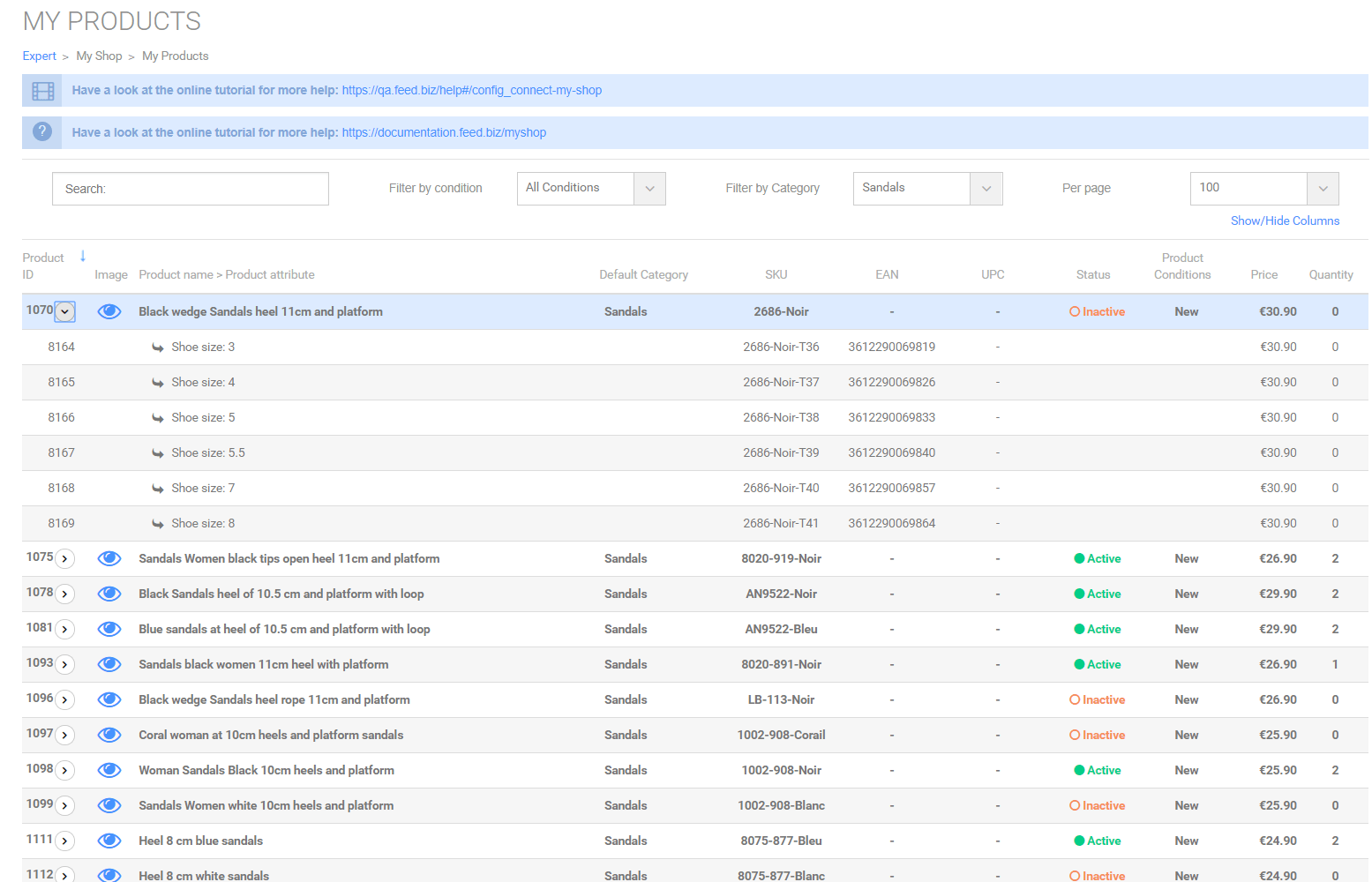
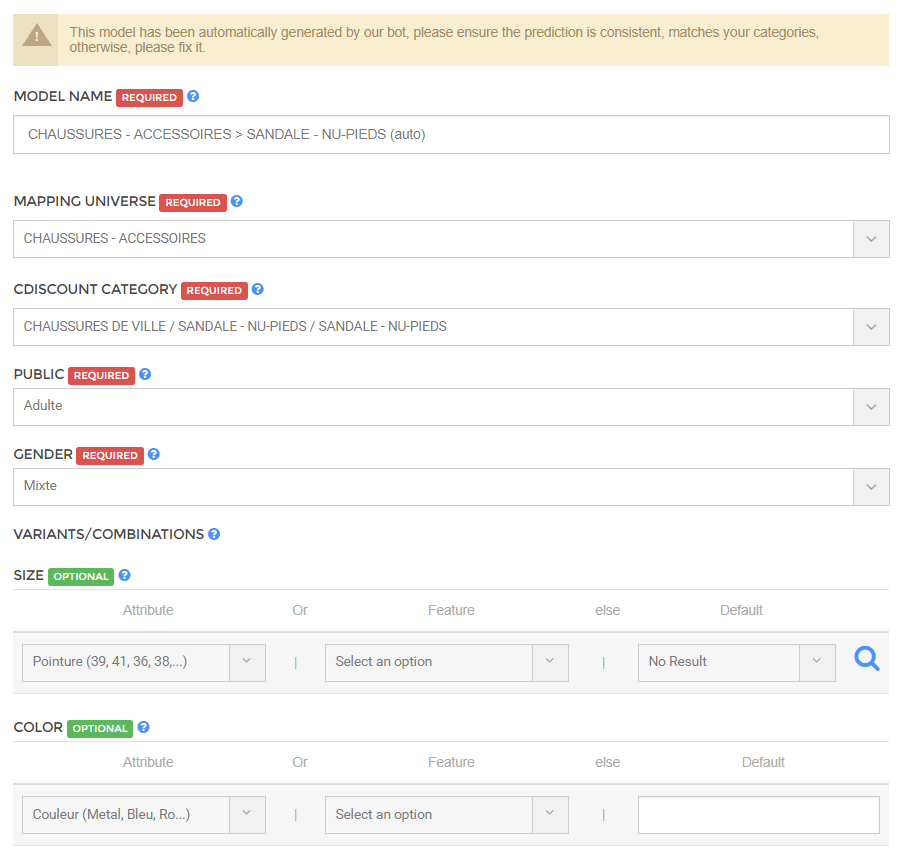
We obtain those predictions ;
We would like to give our thanks to all the contributors and developers of the solutions we have mentioned;
TensortFlow ; https://github.com/tensorflow/tensorflow
Keras ; https://keras.io/
Nltk ; https://www.nltk.org/
CnnText ; https://github.com/dennybritz/cnn-text-classification-tf
FastText ; https://github.com/facebookresearch/fastText/
Thanks to Cdiscount, Cdiscount Flux for their precious help