
Common-Services développe pour Feed.biz et son offre conjointe avec Cdiscount le module Cdiscount Flux pour Prestashop.
Le problématique c’est que Cdiscount dispose de presque 15 000 catégories possibles de produits à ce jour et a référencé depuis sa création 44 millions de produits.
La difficulté pour le marchand est donc de pouvoir classifier ses produits correctement dans ces nombreuses catégories, quand un marchand dispose d’un nombre important de catégories cela peut devenir le parcours du combatant !
Le challenge était donc pour nous initialement de réaliser une catégorisation automatique, mais du fait que Cdiscount ne communique pas les descriptions des produits via les appels API qui permettent de consulter le catalogue, nous n’avons donc pu ne collecter que les noms de produits, ce qui fait un volume d’information plus succin, environ 4 Go de données.
Nous avons donc eu une approche différente mais décidé de modéliser au lieu de catégoriser; ce qui permet au marchand de se voir proposer des modèles génériques correspondant à ses produits ; une liste probables de catégories, le genre du produit, le type de public, les attributs couleurs à envoyer, si la création de variantes/déclinaisons est nécessaire etc.
Pour ce faire nous avons mis en oeuvre les différents frameworks disponibles ; TensortFlow, Keras, Nltk, CnnText, FastText.
La méthodologie est assez simple en soit, il a suffit de normaliser, donc de rendre un texte complexe pour la machine en un texte intelligible, d’une part les catégories en utilisant le code catégorie comme clé et le nom 44 millions de produits classifiés. La procédure de training pour l’ensemble de ces 44 millions de produits a durée 5 heures sur une machine disposant de 32 CPU cadencés à 2.7Ghz et disposant de 64 Go de RAM + 64 Go de RAM et d’un disque de 400 Go pour tampon.
Il a fallut répéter cette opération de multiples fois pour corriger tous les petits détails pouvant poser des problèmes, notamment la ponctuation.
Une fois le résultat parvenu, il était plutôt satisfaisant, nous avons obtenus des résultat pouvant aller jusqu’à 95% de prédictions justes ;
Un exemple ici ;
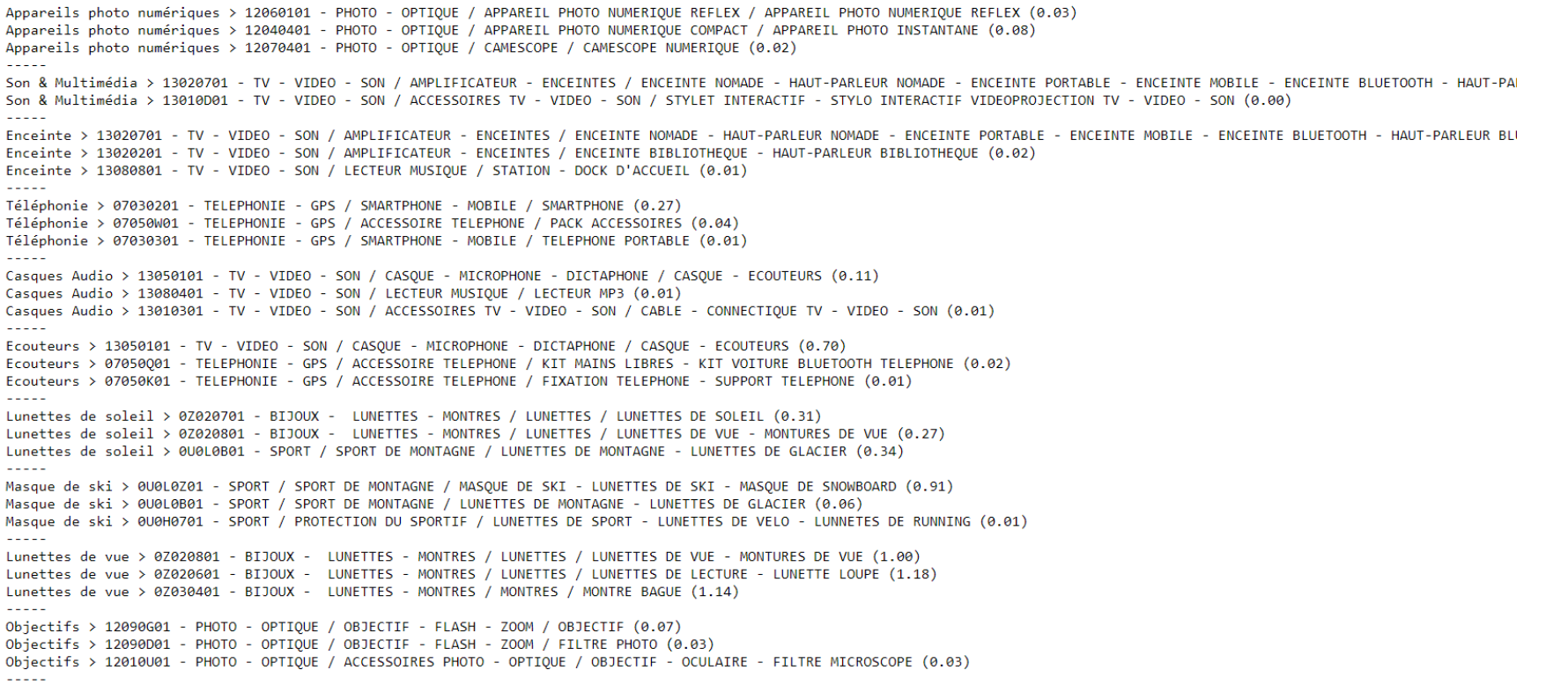
A gauche nous avons la catégorie du marchand qui n’est pas soumise à la learning machine. A droite la catégorie correspondant à Cdiscount. La donnée soumise est le contenu intégral des produits de la catégories du marchant, sans nommer la catégorie, car celle ci pourrait s’appeler par exemple accueil ! Nous voyons que l’intégralité des produits soumis ont reçus comme suggestion les catégories Cdiscount les plus pertinentes.
Une fois ce résultat obtenu, nous avons ainsi pu créer les modèles probables correspondants ;
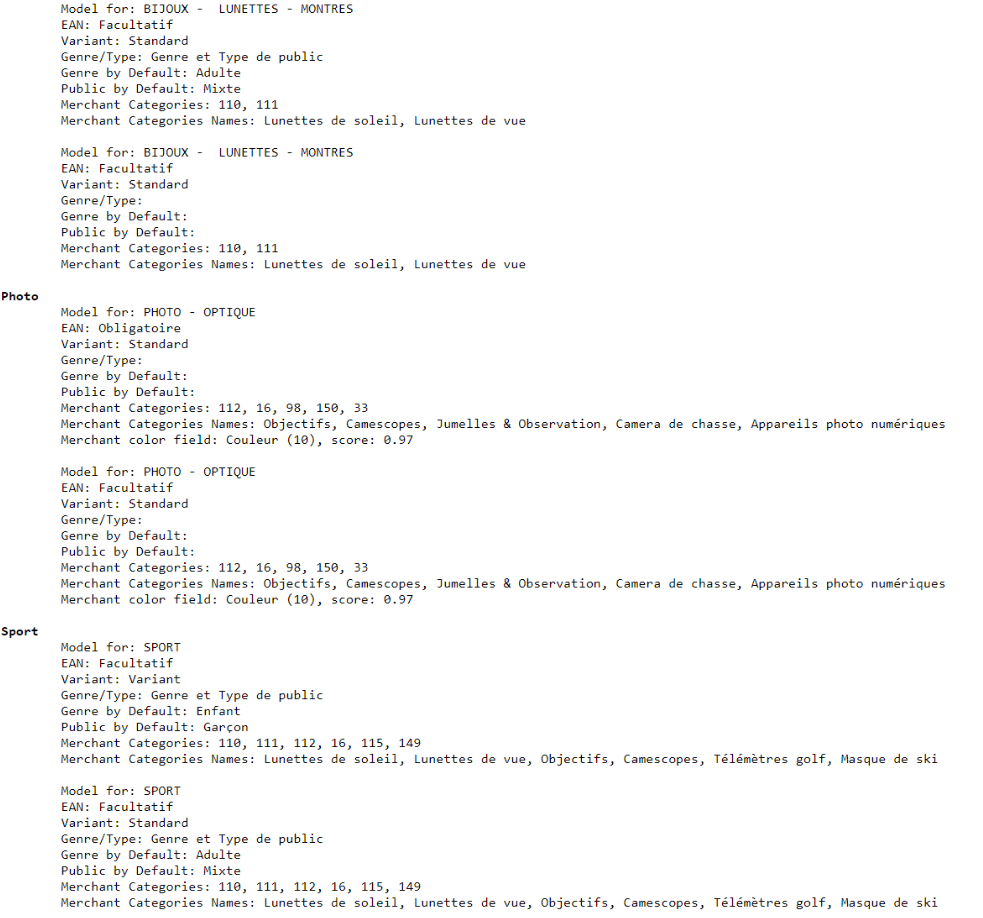
Ainsi, dès la rentrée septembre le marchand qui soumettra un ensemble de catégories se verra proposer les modèles les plus pertinents, il n’aura plus qu’a choisir parmi quelques uns plutôt que d’avoir à réaliser un mapping laborieux sur 15 000 catégories !
Nous avons fait de même pour les champs tailles et couleurs, pour les champs couleurs, nous avons entraîné un modèle sur la base de la négation ; nous avons d’une part inventorié toutes les couleurs et variantes de couleurs, puis, ajouté au modèle les négations les + évidentes, un maximum d’oppositions ; avion, chien, train, assiette etc… le procédé est d’une simplicité enfantine, ne nécessite par de lourds développements.
Le temps nécessaire pour la modélisation quand à lui a nécessité plus de 600 heures de travail !
En pré-production, pour exemple ici un marchand de chaussures, pour la catégorie « Sandales » ;
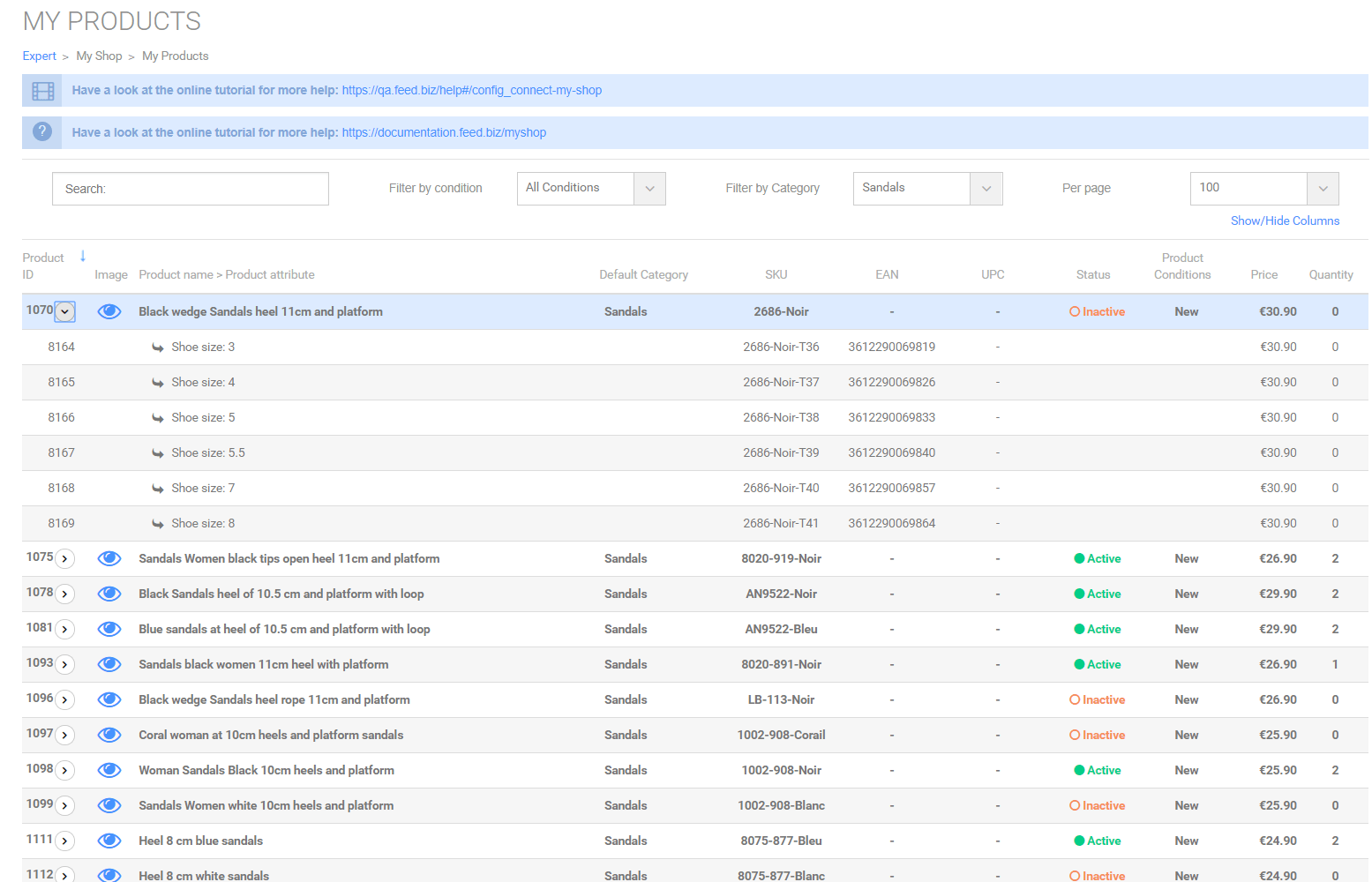
Nous obtenons les prédictions suivantes ;
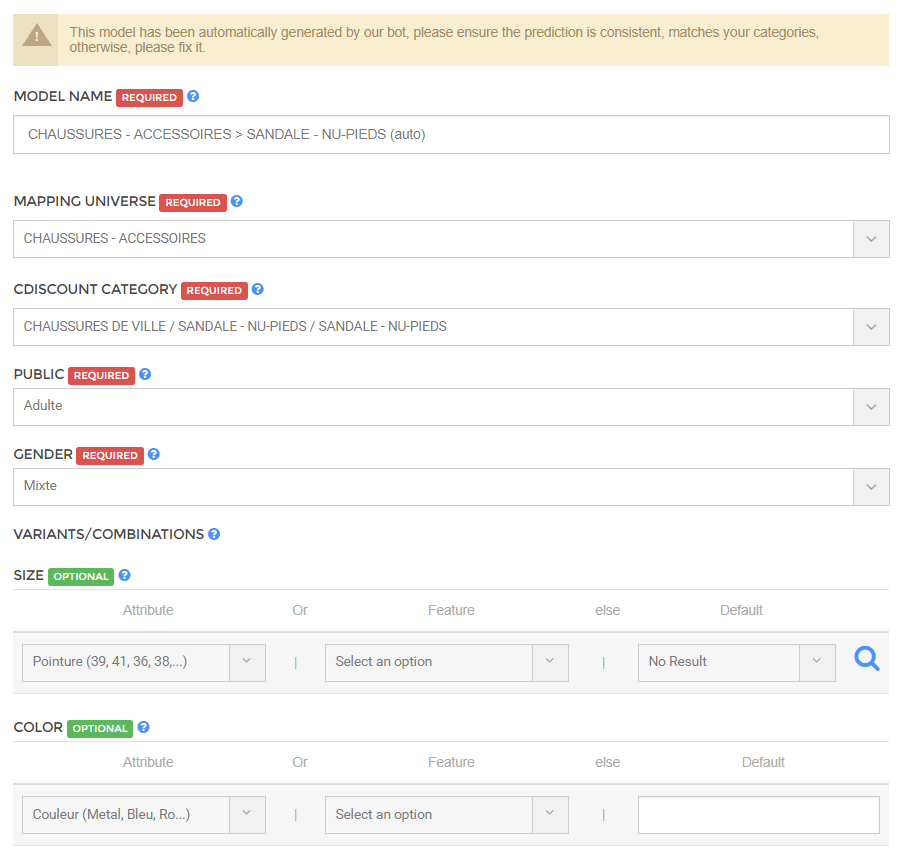
Merci aux contributeurs des solutions mentionnées ;
TensortFlow ; https://github.com/tensorflow/tensorflow
Keras ; https://keras.io/
Nltk ; https://www.nltk.org/
CnnText ; https://github.com/dennybritz/cnn-text-classification-tf
FastText ; https://github.com/facebookresearch/fastText/
Et à merci à Cdiscount, Cdiscount Flux pour leur aide précieuse